
TL;DR
Our team found a UAF vulnerability in Samsung's Android kernel. The vulnerability affected Samsung Android devices starting at Galaxy S9 through Galaxy S25, as well as additional devices (we tested S21, S22, S24, A54). Both Qualcomm and Exynos chipset based devices were impacted.
The vulnerability could be exploited from any untrusted app, and allowed attackers to obtain multiple memory corruption primitives, potentially leading to complete device takeover.
In this post we explain the vulnerability, and exploit primitives that can be derived from it. Note that this post does not describe a full LPE exploit.
LucidBit Labs responsibly disclosed the issue to Samsung, and a fix was issued at the 01-2026 Samsung Android update.
Background
Samsung PROCA (process authenticator) is a proprietary security subsystem built into the kernel of Samsung devices. Its goal is preventing unauthorized processes from executing on Samsung devices. PROCA is a core part of KNOX, a security platform built into the hardware and software of Samsung devices.
PROCA validates process authenticity using FIVE, Samsung’s kernel side integrity subsystem for tracking the trust state of files and the processes that use them. FIVE is based on Linux’s integrity-measurement model, and Samsung extends it.
Under FIVE, each task has a task_integrity object attached to it, storing values such as the task’s current integrity level, user-visible integrity value, etc. That state is updated during normal process and file lifecycle events, including execve(), fork(), executable mappings, and selected integrity-related file operations.
From a vulnerability research perspective, FIVE is an attractive target: widely deployed vendor kernel code, reachable through normal app-accessible interfaces, undocumented behavior, and nontrivial lifetime and state-management logic.
The bug
For the task_integrity object, the kernel exposes a procfs entry allowing user space to look up various information related to the integrity of a process. The procfs entries are exposed under /proc/pid/integrity/ and trigger handlers that access the provided pid's kernel integrity object.
The handlers use this macro to fetch a task's (the kernel object representing a process/thread) integrity object:
#define TASK_INTEGRITY(task) ((task)->integrity)
The macro fetches a raw pointer, and the handlers use that pointer to look up the pid's integrity state without accounting for the integrity's lifetime. The task_integrity is a refcounted object, but no references are taken by the procfs handlers.
During an exec() syscall, the running process is replaced by a newly loaded executable, within the same process (task) container. As part of this, the task_integrity also needs to be replaced, and that happens in __five_bprm_check():
old_tint = TASK_INTEGRITY(task);
...
tint = task_integrity_alloc();
task_integrity_assign(task, tint);
...
task_integrity_put(old_tint); // frees old object
A new task_integrity is allocated and assigned, and the old one is freed.
This also explains the likely reason why the bug exists - the above code first allocates and assigns a new integrity to a process, and only after that the old integrity object is freed. However, Android runs a fully preemptive kernel - a process can be scheduled out at nearly any time, so the following sequence of events is possible (in theory, for now):
- A process forks a child
- The parent reads the child's
/proc/child pid/integrity/*, and triggers a handler that fetches the integrity object, then schedules out. - The child calls
execve(), triggering the creation of a new integrity, and freeing the old one. - The parent resumes execution, and operates on the old (freed) integrity object.
If you hit just the right timing (and add some scheduling magic powder), this scenario happens, leading to a various operations done on the freed integrity object's memory.
Let's look at one of the handlers to see this more clearly:
static int proc_integrity_value_read(struct seq_file *m, ...,
struct task_struct *task)
{
seq_printf(m, "%x\n", task_integrity_user_read(TASK_INTEGRITY(task)));
return 0;
}
The handler fetches the integrity pointer, and then calls task_integrity_user_read() on it.
So this can happen:
proc_integrity_value_read()takes the pointer viaTASK_INTEGRITY(task).proc_integrity_value_read()is scheduled out before performingtask_integrity_user_read().- The target task executes
execve(), specificallytask_integrity_put(old_tint), freeing the original struct. proc_integrity_value_read()resumes and callstask_integrity_user_read()with a pointer to freed memory.
While relatively straightforward, the race window is tiny - the process running proc_integrity_value_read() needs to be scheduled out just at the right time (within a window consisting of a couple of opcodes), and be scheduled out for long enough to gain control of the memory.
Structures Layout & Handlers Code
To better understand the implications, let's look at the relevant code:
#define TASK_INTEGRITY(task) ((task)->integrity)
Relevant part of the task struct:
struct task_struct {
...
pid_t pid;
pid_t tgid;
unsigned int in_execve:1;
...
struct task_integrity *integrity;
...
};
And the task_integrity:
struct task_integrity {
enum task_integrity_value user_value;
enum task_integrity_value value;
atomic_t usage_count;
spinlock_t value_lock;
struct integrity_label *label;
...
enum task_integrity_reset_cause reset_cause;
struct file *reset_file;
};
An important note is that task_integrity is allocated via its own dedicated cache, task_integrity_cache.
Procfs handlers implementations
First, the previously mentioned proc_integrity_value_read():
static int proc_integrity_value_read(struct seq_file *m, ...,
struct task_struct *task)
{
seq_printf(m, "%x\n", task_integrity_user_read(TASK_INTEGRITY(task)));
return 0;
}
static inline enum task_integrity_value task_integrity_user_read(
struct task_integrity *intg)
{
return intg->user_value;
}
Next, proc_integrity_label_read:
struct integrity_label {
uint16_t len;
uint8_t data[];
};
static int proc_integrity_label_read(struct seq_file *m, ...,
struct task_struct *task)
{
struct integrity_label *l;
spin_lock(&TASK_INTEGRITY(task)->value_lock);
l = TASK_INTEGRITY(task)->label;
spin_unlock(&TASK_INTEGRITY(task)->value_lock);
if (l) {
size_t data_len = l->len * 2;
...
bin2hex(buffer, l->data, size / 2);
seq_commit(m, size);
}
...
}
And last, the proc_integrity_reset_file route:
static int proc_integrity_reset_file(struct seq_file *m, ...,
struct task_struct *task)
{
char *tmp;
char *pathname;
if (!TASK_INTEGRITY(task)->reset_file) {
seq_printf(m, "%s", "");
return 0;
}
tmp = (char *)__get_free_page(GFP_KERNEL);
pathname = d_path(&TASK_INTEGRITY(task)->reset_file->f_path,
tmp, PAGE_SIZE);
...
}
Digging for primitives
Primitive 1: proc_integrity_value_read()
This is the most straightforward primitive here.
proc_integrity_value_read() ultimately consumes task_integrity->user_value, which is at offset 0. If the old object is freed and the slot is reclaimed before the reader resumes, the procfs path will print whatever now occupies the first word of the old task_integrity allocation.
Here's an example of how the memory looks after the freed-and-reallocated memory was filled with 0x42:
[ 4211.877634] Pointer value at intg: 000000009440eb3f, value: 4242424242424242
[ 4211.877637] Next qword 0: 4242424242424242
As a primitive, this is narrow but attractive:
- No crash risk
- DWORD leak
- Creates a potential "did reclaim actually happen" oracle, that may be used with other primitives to avoid crashes
The downside is the very tight race. The attacker needs to:
- Schedule the reader out within the tiny window. Within that window (before its rescheduled):
- Free the memory (back to the page allocator, since freeing task_integrity returns the memory to the dedicated task_integrity_cache).
- Reallocate with something worth leaking.
Scheduling Voodoo, Slab Art
The Android kernel is preemptive - that means any process can be scheduled out at (almost) any time. This makes tiny race windows possible to hit, even if challenging. There are multiple effective methods that can be leveraged to controlling timing, a lot of which are described in great technical posts and talks.
Since the task_integrity uses its own dedicated cache, achieving a valuable UAF requires a cross-cache attack in order to control the freed memory. Here also, there are known techniques that can be used to get the freed object allocated as a different type of object.
The small race windows combined with the integrity object using a dedicated cache poses a significant exploitation challenge. One needs to hit the tiny race window, schedule the 'using' thread for long enough for the freed memory to be reallocated as a different type of object, and avoid all sorts of crashes that can take place if things don't work as expected.
We will not deep dive into these challenges, but we will mention that to successfully hit the timing windows and control the freed memory, we combined multiple techniques (most of which are public), and a lot of trial and error took place. We will also show how sometimes a different exploitation path (that originally looks unlikely) can end up solving at least some of these challenges.
Primitive 2: Arbitrary(?) Call
This one is highly interesting when initially inspecting the vulnerability.
proc_integrity_reset_file() eventually reaches:
pathname = d_path(&TASK_INTEGRITY(task)->reset_file->f_path, tmp, PAGE_SIZE);
d_path() uses a (potentially) freed task_integrity, which leads to a function pointer call:
if (path->dentry->d_op && path->dentry->d_op->d_dname &&
(!IS_ROOT(path->dentry) || path->dentry != path->mnt->mnt_root))
return path->dentry->d_op->d_dname(path->dentry, buf, buflen);
If the old task_integrity has already been freed, then reset_file is potentially also freed.
The critical part inside d_path() is this d_dname() call:
if (path->dentry->d_op && path->dentry->d_op->d_dname &&
(!IS_ROOT(path->dentry) || path->dentry != path->mnt->mnt_root))
return path->dentry->d_op->d_dname(path->dentry, buf, buflen);
with controlled memory, this leads to calling a function from a freed pointer - interesting. Lets look at the relevant structs:
struct file {
...
struct path f_path;
struct inode *f_inode;
const struct file_operations *f_op;
...
atomic_long_t f_count;
...
};
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
};
struct dentry {
...
struct dentry *d_parent;
struct qstr d_name;
struct inode *d_inode;
...
const struct dentry_operations *d_op;
...
};
struct dentry_operations {
...
char *(*d_dname)(struct dentry *, char *, int);
...
};
The naive way to go about it - control the memory of the freed integrity object - has the same two very hard challenges:
- tint uses a dedicated cache
- the race window is tiny
Combined, these make it very hard to achieve reliable controlled memory, and often end up with a kernel panic.
However, there is another way to go about things. The tint free path also calls fput() on the reset_file. The race window here is significantly larger, and it also avoids the need to reclaim the tint from the dedicated cache - which makes the reset_file a more interesting UAF target.
To hit the file UAF, reset_file needs to have a refcount of 1. Normally, processes are executed / forked, and task_integrity_copy() carries reset_file forward with get_file(from->reset_file), fork() etc. In practice, the reset file for any app we inspected (long running or newly executed) is bigger than one, making the file UAF route irrelevant.
Irrelevant - or is it?
When inspecting the code paths that set / modify the reset_file, we saw an interesting path in execve:
execve(path)
-> do_open_execat() succeeds
// bprm->file now holds the opened executable
-> exec_binprm()
-> five_bprm_check()
// assigns a fresh task_integrity
-> search_binary_handler()
-> -ENOEXEC
// no binary-format handler accepts the file
-> task_integrity_delayed_reset(current, CAUSE_EXEC, bprm->file)
-> task_integrity_set_reset_reason()
-> get_file(file)
-> tint->reset_file = file
-> free_bprm()
-> fput(bprm->file)
Something interesting happens when exec is called with a target file that passes the early execute checks but fails actual program loading: regular, executable, allowed by policy, and on an executable mount, but not ELF, not a valid #! script, and not accepted by any other binfmt handler.
five_bprm_check() runs before search_binary_handler() proves the file is loadable, so a late -ENOEXEC leaves the task with a fresh tint whose reset_file is the failed executable. task_integrity_set_reset_reason() takes one file reference, and free_bprm() drops the temporary bprm->file reference. After the failed exec unwinds, only tint->reset_file still references the file.
We found a unique file that existed on all our test devices and satisfied these requirements, /system/bin/monkey: it is a regular 0755 system file on an executable mount, but it is plain text, not ELF, and has no #! interpreter line. Directly executing it reaches search_binary_handler(), returns -ENOEXEC, and causes FIVE to record /system/bin/monkey as the
CAUSE_EXEC reset_file.
A simple call to execve('/system/bin/monkey', ...); leads to the calling app having a fresh reset file with refcount of 1.
This removes the reset_file refcount > 1 blocker.
The next step
This shows how the memory layout needs to look:
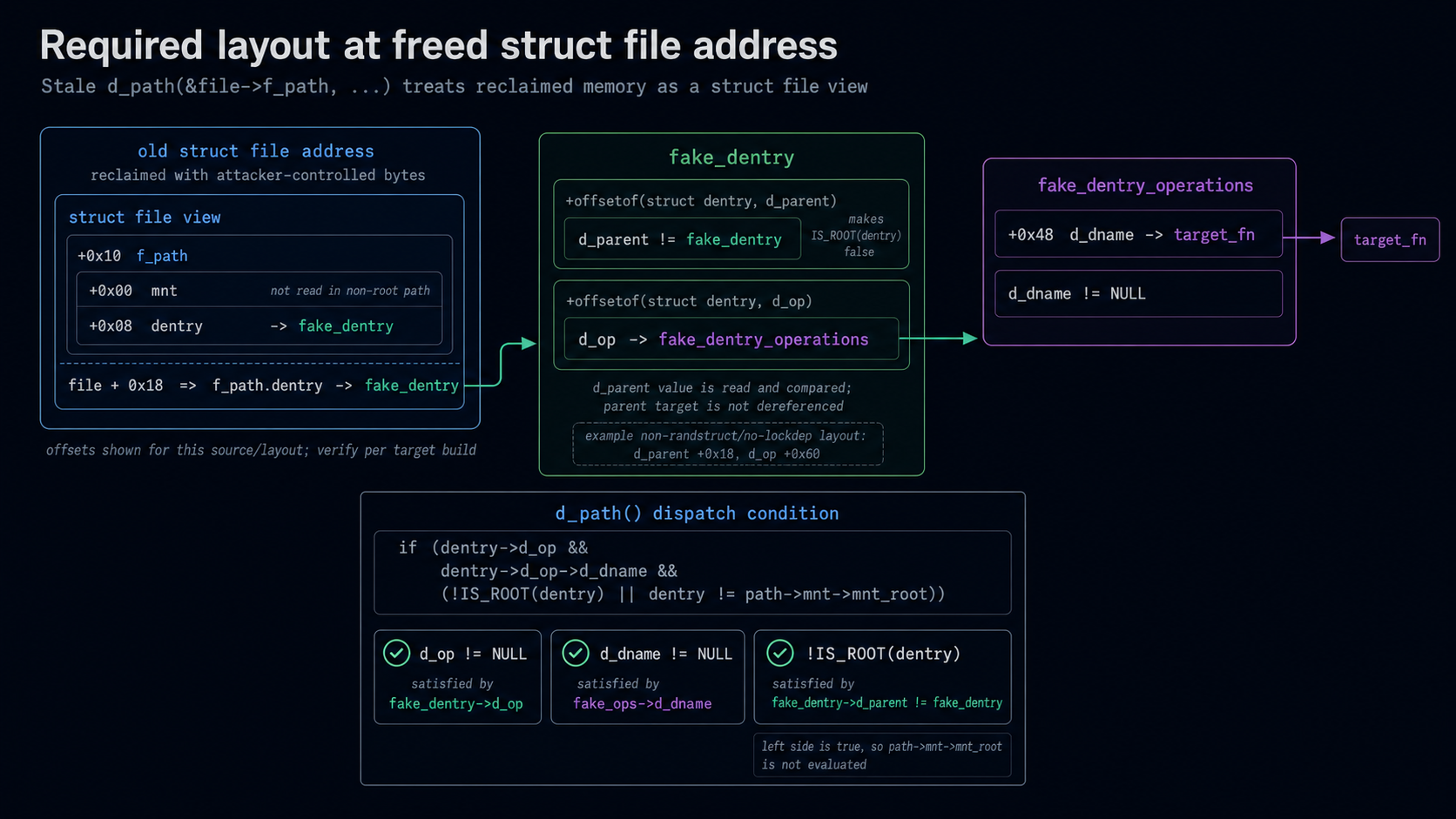
Following this, an attacker can:
- Get the reset_file's refcount to 1
- Use the infoleak primitive to bypass KASLR
- Hit the race timing
- Reallocate the freed memory in a fully controlled manner
Then d_dname() would point to an attacker controlled address.
(1) Is trivial and deterministic (once you figure out the /system/bin/monkey trick). (2) Is difficult due to the limitations of the infoleak, but there's no risk of crash. (3) + (4) combined are difficult. The process needs to be scheduled out for long enough to free the file, and allocate it as controlled memory.
But after all that, attackers get the arbitrary call primitive, right? Not really.
Enter CFI
Modern Android kernels support Control Flow Integrity. The basic idea is that indirect calls are not allowed to jump to arbitrary code - before calling a function pointer, the compiler inserts a runtime check that verifies that the target function has the expected prototype.
So instead of doing only:
d_op->d_dname(struct dentry *, char *, int);
the generated code does something like:
target = d_op->d_dname;
if (!cfi_type_matches(target, expected_d_dname_prototype))
cfi_failure();
target(struct dentry *, char *, int);
With KCFI, Clang assigns a type identifier to each valid indirect-call target, fitting the function’s prototype. The call site also knows the type it expects. Immediately before the indirect branch, the generated code checks that the target function carries the matching type ID. If the IDs do not match, the kernel reports a CFI violation and panics.
This means that corrupting a function pointer is not enough to redirect execution to any chosen kernel function or gadget. The replacement target must be a valid indirect-call target with a compatible prototype. CFI therefore narrows the attacker’s usable target set from “any executable kernel address” to “functions that look type-compatible for this call site.”
In our case, the defconfig indeed includes CONFIG_CFI_CLANG=y, and the kernel Makefile includes:
ifdef CONFIG_CFI_CLANG
CC_FLAGS_CFI := -fsanitize=kcfi
KBUILD_CFLAGS += $(CC_FLAGS_CFI)
endif
A (truly) dead end
With CFI enabled, there are very few functions allowed to be called instead of d_dname (depending on the specific kernel version). Practically, we couldn't find any interesting function to call here, and this exploit primitive looks like a dead end.
Primitive 3: proc_integrity_label_read()
static int proc_integrity_label_read(struct seq_file *m, ...,
struct task_struct *task)
{
struct integrity_label *l;
spin_lock(&TASK_INTEGRITY(task)->value_lock);
l = TASK_INTEGRITY(task)->label;
spin_unlock(&TASK_INTEGRITY(task)->value_lock);
if (l) {
size_t data_len = l->len * 2;
...
bin2hex(buffer, l->data, size / 2);
seq_commit(m, size);
}
...
}
While there's a potential read primitive here, the more interesting primitive here is the spin lock and unlock.
On Android kernel, spinlock_t's implementation is based on the Linux queued spinlock implementation. A queued spinlock is small: the whole lock state is stored in a single 32-bit word - a low locked byte, a pending byte/bit, and a queue tail for contending lockers.
The fast path for queued_spin_lock() is an atomic compare/exchange from 0 to _Q_LOCKED_VAL, and queued_spin_unlock() releases the lock by storing 0 into the locked byte. The slow path is more interesting: it can set pending, update locked_pending, and exchange the queue tail field as other CPUs contend on the same lock.
So one potential write primitive looks something like this:
- Reader scheduled out after reading the integrity, but before calling spinlock().
- execve() replaces task->integrity
- task_integrity_put(old_tint) frees old_tint
- old_tint slot is freed, and another object is allocated instead
- Reader resumes
- spin_lock(old_tint->value_lock) writes into the reclaimed object
For this primitive, we need to consider several factors:
- The lock is at offset 0xc, so we need the freed task_integrity slot to be reclaimed by an object where offset 0xc overlaps something interesting.
- The value is used as a spinlock. This means the write is produced by spinlock mechanism - locked byte transitions, pending transitions, tail updates.
- Also, depending on the memory contents of the reclaimed lock, the write may be transient - in the uncontended fast path, lock acquisition can write the low locked byte and the matching unlock can clear it again. If nothing observes the intermediate value, the final memory is unchanged.
While significantly constrained, the primitive can be valuable - a small write into a pointer, a refcount, a length, or a flags field. This could be leveraged into a heap OOB access, another UAF, or other primitives.
There is also a scheduling angle. The spinlock can also be abused as timing control. If the stale lock word is non-zero, or if another CPU is made to contend on the same lock, the procfs reader may spin instead of immediately reaching the label load. That is risky, as if the lock isn't free within a 10-20 seconds, a hard lockup panic crashes the device. But controlled spinning is also a strong way to widen the race: the reader has already committed to the old lock address, but progress is delayed while another CPU performs the free and reclaim.
Closing
Modified code, especially one related to complex mechanisms, is always an interesting area to look for vulnerabilities in. FIVE is a part of the Samsung KNOX security suite, and as we saw, protections can increase the attack surface.
This bug remained hidden since FIVE was introduced as far as we know, and affected devices released 8 years ago up to the latest models. It affected every Samsung device we tested, both Exynos and Qualcomm based, and every Android version we tested.
This research also demonstrated common difficulties related to kernel exploitation of race conditions - short race windows combined with the need to reallocate freed memory in a different cache. It also shows how kernel CFI was a highly effective mitigation in this case, practically blocking an arbitrary call primitive. In spite of that, other powerful primitives did exist.
LucidBit Labs
Our research team carries out offensive security engagements, tackling sensitive and complex software systems the same way a sophisticated attacker does.
Reach out to us if you want your sensitive systems looked at.